App 执行后台任务(UIBackgroundTask)时崩溃,错误信息:BUG IN CLIENT OF LIBDISPATCH: Unbalanced call to dispatch_group_leave()
内容概览
- 前言
- 开始和结束 UIBackgroundTask
- 崩溃行附近的 CompletionHandler 调用
- 总结
前言
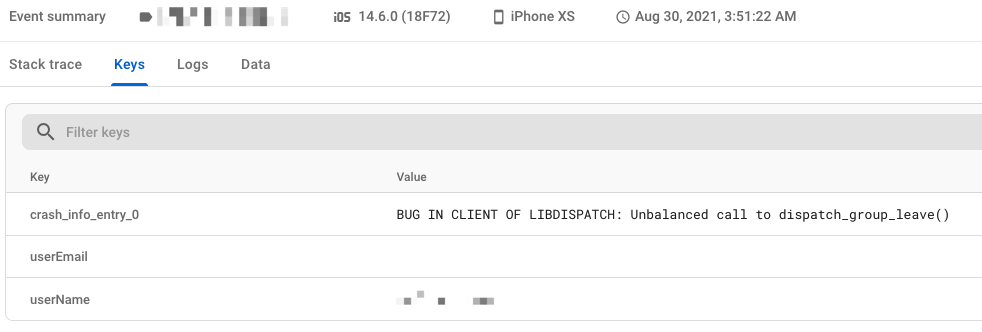
应用在执行后台任务时,莫名其妙地就崩溃了。登录 Firebase 查看 Crashlytics 控制台,在 crash_info_entry_0 这个 Key 对应的 Value 处看到一个令人困惑的错误:BUG IN CLIENT OF LIBDISPATCH: Unbalanced call to dispatch_group_leave()。
查看了相关的代码,并没有调用 dispatch_group 或相关的方法。好吧,先请强大的 Google 帮帮我~
Google 的搜索结果里面有一条记录是苹果官方的开发者论坛:crash iOS 14 - Unbalanced call to dispatch_group_leave()
其中,GaelPB 的推测观点 是比较接近最终答案的(不过,不正确)。
在此,Ficow 先说明问题的成因:
App 在 iOS 14 中执行后台任务时,completionHandler 被多次调用,就会导致崩溃。
这是如何调查出来的呢?问题如何解决呢?希望后文中 Ficow 的 debug 思路能够对您有帮助~
开始和结束 UIBackgroundTask
起初,Ficow 怀疑问题是由于 后台上传管理器 (BackgroundUploadManager)中任务的开始和结束 API 调用不匹配导致的。
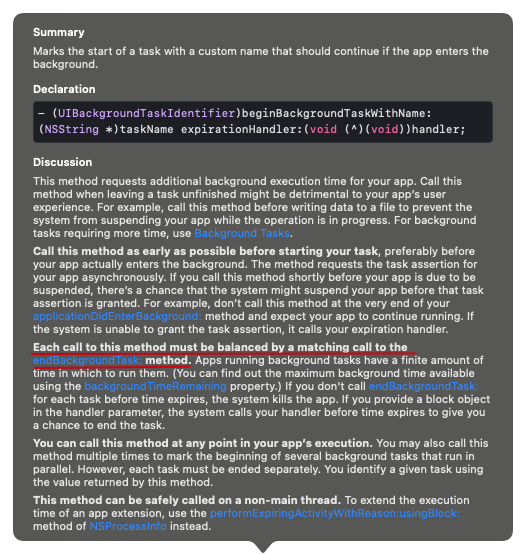
App 在开始执行后台任务前,需要调用 UIApplication 单例的以下方法创建一个后台任务:
- (UIBackgroundTaskIdentifier)beginBackgroundTaskWithName:(NSString *)taskName expirationHandler:(void (^)(void))handler;
在任务结束时,还需要调用 UIApplication 单例的以下方法手动结束后台任务:
- (void)endBackgroundTask:(UIBackgroundTaskIdentifier)identifier;
官方文档中注明了,开始和结束后台任务的 API 调用需要平衡:
为了确认问题是否由此导致,Ficow 采取了以下措施:
- 将
endBackgroundTask方法封装在了一个公用方法中,然后将老旧项目中所有调用endBackgroundTask方法的调用点都改为调用这个公用方法。 - 为了避免后台多线程同时访问,这个方法还被加了锁。
- 除此之外,这个方法还被加上了崩溃追踪事件,方便在后续的崩溃中查看和分析
endBackgroundTask方法被调用的情况。
以下是示例代码:
- 为了简化锁的处理,使用了
@synchronized; - 调用
[UIApplication.sharedApplication backgroundTimeRemaining]可以获取后台任务还剩下多少可用时间,然后写入到崩溃日志中;
- (void)endBackgroundTask {
@synchronized(self.backgroundTaskLock) {
if (self.scannerBackgroundTaskId == UIBackgroundTaskInvalid) return;
// 用崩溃日志记录 scannerBackgroundTaskId、后台任务执行了多长时间
[[UIApplication sharedApplication] endBackgroundTask:self.scannerBackgroundTaskId];
self.scannerBackgroundTaskId = UIBackgroundTaskInvalid;
}
}
这些改动上线一段时间之后,Ficow 对后续的崩溃日志进行了分析。令人失望的是,即使后台任务没有超时,App也会 crash,而且错误信息依旧。好吧,那就是其他问题导致的崩溃,我们继续调查~
崩溃行附近的 CompletionHandler 调用
多次的改动之后,同样的 crash ,问题产生的位置却不断变化。不过,有一点始终没变,崩溃总是发生在了某一行代码之后:
if (completionHandler) {
completionHandler(UIBackgroundFetchResultNewData);
}
然后,Ficow 开始怀疑这个 completionHandler 的来源,而且好奇这个 completionHandler 到底在做什么。
最终,发现了以下 2 个 completionHandler 的来源:
- 后台刷新方法
- (void)application:(UIApplication *)application performFetchWithCompletionHandler:(void (^)(UIBackgroundFetchResult result))completionHandler;
- 远程推送的接收回调方法
- (void)application:(UIApplication *)application didReceiveRemoteNotification:(NSDictionary *)userInfo fetchCompletionHandler:(void (^)(UIBackgroundFetchResult result))completionHandler;
发现问题的来源之后,Ficow 借助远程推送终于成功重现了崩溃问题(之前连重现都做不到 😅)。顺便推荐一款可以方便地发送远程推送到 iOS 设备的工具:lola - Github,亲测非常好用!!!
此时,疑惑更多了!为什么会将这 2 个方法的完成回调传给后台上传管理器?(先搞清楚需求)
答:希望应用可以借助后台刷新和远程推送启动,然后继续上传任务。如果应用很快就被切换到后台,后台任务还可以继续运行 30 秒,这为上传任务争取了很多时间。
那么,崩溃到底是不是由于调用
completionHandler引起的呢? (再次确认问题成因)
Ficow 在 completionHandler 被调用之前写了一个标记到崩溃日志中。果然,后续的所有崩溃日志都是在 completionHandler 不为空的情况下发生的。
问题成因已经确定了,那么,我们是不是直接移除这个完成回调就搞定问题了呢?(优先考虑简单可行的解决方案)
答:不行!如果是这样,很多后台任务执行的机会就会大幅度减少,原本可以很快完成的后台任务,很久才能完成,甚至不能完成(应用的进程被系统挂起)。之后,用户肯定会抱怨应用的上传功能太差劲,这并不是我们想要的结果。
如果不移除,我们如何根除问题呢?(方案受到限制)
答:那就只能找出为什么 completionHandler 执行后就会 crash 的最根本原因!
此时,Ficow 有一个新的猜想:
completionHandler 执行的时间太晚,所以在调用时导致了崩溃。
那么,我们可以为 completionHandler 的调用加一个计时器,让后台任务在运行 27 秒左右就停止:
- (void (^)(UIBackgroundFetchResult))completionHandlerCalledBeforeAppTermination:(void (^)(UIBackgroundFetchResult))completionHandler {
__weak __typeof(self) weakedSelf = self;
NSDate *start = [NSDate date];
NSTimeInterval intervalBeforeAppTermination = 27;
NSTimer *timer = [NSTimer timerWithTimeInterval:intervalBeforeAppTermination repeats:NO block:^(NSTimer * _Nonnull timer) {
[AnalyticsEvent logForCrashWithFormat:@"timer expires"];
__strong __typeof(weakedSelf) self = weakedSelf;
isCompletionHandlerCalled = YES;
[AnalyticsEvent logForCrashWithFormat:@"completionHandler called 1"];
completionHandler(UIBackgroundFetchResultNewData);
[timer invalidate];
[self.completionHandlerTimers removeObject:timer];
}];
timer.tolerance = 1;
[[NSRunLoop currentRunLoop] addTimer:timer forMode:NSRunLoopCommonModes];
[self.completionHandlerTimers addObject:timer];
void (^wrappedCompletionHandler)(UIBackgroundFetchResult) = ^(UIBackgroundFetchResult fetchResult) {
NSTimeInterval interval = [[NSDate date] timeIntervalSinceDate:start];
[AnalyticsEvent logForCrashWithFormat:@"wrappedCompletionHandler called, interval: %f", interval];
__strong __typeof(weakedSelf) self = weakedSelf;
[AnalyticsEvent logForCrashWithFormat:@"completionHandler called 2"];
completionHandler(fetchResult);
[timer invalidate];
[self.completionHandlerTimers removeObject:timer];
};
return wrappedCompletionHandler;
}
然后,将这个包装 completionHandler 的 completionHandler 传给下游。如果下游手动调用了completionHandler,就取消计时器。
结果,这样处理之后,问题依然存在!请注意,即使倒计时改为了 10 秒,问题也依然存在。
不过,功夫不负有心人!这一次的改动上线之后,通过查看多个 crash 日志中的内容,Ficow 又发现了另一个特征:
- 每次 crash 发生的时候,日志里面都同时出现了
completionHandler called 1和completionHandler called 2。
也就是说,下游调用了 completionHandler,而且计时器倒计时结束后也调用了 completionHandler。completionHandler 实际上被调用了 2 次!!!
好吧,现在就很好办了!加上一个标识,只允许 completionHandler 被调用一次:
- (void (^)(UIBackgroundFetchResult))completionHandlerCalledBeforeAppTermination:(void (^)(UIBackgroundFetchResult))completionHandler {
__block BOOL isCompletionHandlerCalled = NO; // 标识
__weak __typeof(self) weakedSelf = self;
NSDate *start = [NSDate date];
NSTimeInterval intervalBeforeAppTermination = 27;
NSTimer *timer = [NSTimer timerWithTimeInterval:intervalBeforeAppTermination repeats:NO block:^(NSTimer * _Nonnull timer) {
[AnalyticsEvent logForCrashWithFormat:@"timer expires"];
if (isCompletionHandlerCalled) { return; } // 防止重复调用
__strong __typeof(weakedSelf) self = weakedSelf;
isCompletionHandlerCalled = YES; // 防止重复调用
[AnalyticsEvent logForCrashWithFormat:@"completionHandler called 1"];
completionHandler(UIBackgroundFetchResultNewData);
[timer invalidate];
[self.completionHandlerTimers removeObject:timer];
}];
timer.tolerance = 1;
[[NSRunLoop currentRunLoop] addTimer:timer forMode:NSRunLoopCommonModes];
[self.completionHandlerTimers addObject:timer];
void (^wrappedCompletionHandler)(UIBackgroundFetchResult) = ^(UIBackgroundFetchResult fetchResult) {
NSTimeInterval interval = [[NSDate date] timeIntervalSinceDate:start];
[AnalyticsEvent logForCrashWithFormat:@"wrappedCompletionHandler called, interval: %f", interval];
if (isCompletionHandlerCalled) { return; } // 防止重复调用
isCompletionHandlerCalled = YES; // 防止重复调用
__strong __typeof(weakedSelf) self = weakedSelf;
[AnalyticsEvent logForCrashWithFormat:@"completionHandler called 2"];
completionHandler(fetchResult);
[timer invalidate];
[self.completionHandlerTimers removeObject:timer];
};
return wrappedCompletionHandler;
}
不出所料,这一次的改动上线之后,crash 被彻底终结了!
显然,我们不再需要这个计时器。问题是由于下游重复调用 completionHandler 导致的,那么只需要保留 completionHandler 的包装,防止重复调用即可。
总结
调试线上 bug,需要足够的耐心。一般来说,这些做法可以帮助我们尽快定位和解决问题:
- 通过
崩溃日志,了解如何重现问题(用户的操作步骤 或 代码的执行路径); - 如果崩溃日志缺少有用的内容,则
按需添加日志(比如:是否初次启动、是否有异常的缓存数据、代码执行的具体路径、线程信息等); - 多次更新代码并上线监测,然后根据最新的崩溃情况和日志来
缩小问题的范围; - 利用
搜索引擎搜索相关的问题,也许可以参考他人的思路;
参考内容:
crash iOS 14 - Unbalanced call to dispatch_group_leave()
lola - Github
觉得不错?点个赞呗~
转载声明:本站文章如无特别说明,皆为原创。转载请注明:Ficow Shen's Blog